Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Microsoft isn’t resting its AI success on the laurels of its partnership with OpenAI.
No, far from it. Instead, the company often known as Redmond for its headquarters location in Washington state today came out swinging with the release of 3 new models in its evolving Phi series of language/multimodal AI.
The three new Phi 3.5 models include the 3.82 billion parameter Phi-3.5-mini-instruct, the 41.9 billion parameter Phi-3.5-MoE-instruct, and the 4.15 billion parameter Phi-3.5-vision-instruct, each designed for basic/fast reasoning, more powerful reasoning, and vision (image and video analysis) tasks, respectively.
All three models are available for developers to download, use, and fine-tune customize on Hugging Face under a Microsoft-branded MIT License that allows for commercial usage and modification without restrictions.
Amazingly, all three models also boast near state-of-the-art performance across a number of third-party benchmark tests, even beating other AI providers including Google’s Gemini 1.5 Flash, Meta’s Llama 3.1, and even OpenAI’s GPT-4o in some cases.
That performance, combined with the permissive open license, has people praising Microsoft on the social network X:
Let’s review each of the new models today, briefly, based on their release notes posted to Hugging Face
Phi-3.5 Mini Instruct: Optimized for Compute-Constrained Environments
The Phi-3.5 Mini Instruct model is a lightweight AI model with 3.8 billion parameters, engineered for instruction adherence and supporting a 128k token context length.
This model is ideal for scenarios that demand strong reasoning capabilities in memory- or compute-constrained environments, including tasks like code generation, mathematical problem solving, and logic-based reasoning.
Despite its compact size, the Phi-3.5 Mini Instruct model demonstrates competitive performance in multilingual and multi-turn conversational tasks, reflecting significant improvements from its predecessors.
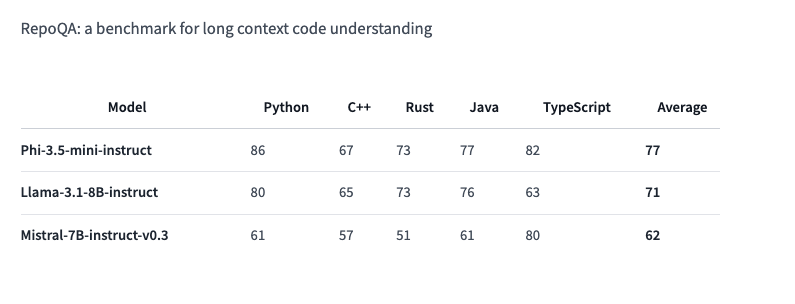
It boasts near-state-of-the-art performance on a number of benchmarks and overtakes other similarly-sized models (Llama-3.1-8B-instruct and Mistral-7B-instruct) on the RepoQA benchmark which measures “long context code understanding.”
Phi-3.5 MoE: Microsoft’s ‘Mixture of Experts’
The Phi-3.5 MoE (Mixture of Experts) model appears to be the first in this model class from the firm, one that combines multiple different model types into one, each specializing in different tasks.
This model leverages an architecture with 42 billion active parameters and supports a 128k token context length, providing scalable AI performance for demanding applications. However, it operates nly with 6.6B active parameters, according to the HuggingFace documentation.
Designed to excel in various reasoning tasks, Phi-3.5 MoE offers strong performance in code, math, and multilingual language understanding, often outperforming larger models in specific benchmarks, including, again, RepoQA:

It also impressively beats GPT-4o mini on the 5-shot MMLU (Massive Multitask Language Understanding) across subjects such as STEM, the humanities, the social sciences, at varying levels of expertise.

The MoE model’s unique architecture allows it to maintain efficiency while handling complex AI tasks across multiple languages.
Phi-3.5 Vision Instruct: Advanced Multimodal Reasoning
Completing the trio is the Phi-3.5 Vision Instruct model, which integrates both text and image processing capabilities.
This multimodal model is particularly suited for tasks such as general image understanding, optical character recognition, chart and table comprehension, and video summarization.
Like the other models in the Phi-3.5 series, Vision Instruct supports a 128k token context length, enabling it to manage complex, multi-frame visual tasks.
Microsoft highlights that this model was trained with a combination of synthetic and filtered publicly available datasets, focusing on high-quality, reasoning-dense data.
Training the new Phi trio
The Phi-3.5 Mini Instruct model was trained on 3.4 trillion tokens using 512 H100-80G GPUs over 10 days, while the Vision Instruct model was trained on 500 billion tokens using 256 A100-80G GPUs over 6 days.
The Phi-3.5 MoE model, which features a mixture-of-experts architecture, was trained on 4.9 trillion tokens with 512 H100-80G GPUs over 23 days.
Open-source under MIT License
All three Phi-3.5 models are available under the MIT license, reflecting Microsoft’s commitment to supporting the open-source community.
This license allows developers to freely use, modify, merge, publish, distribute, sublicense, or sell copies of the software.
The license also includes a disclaimer that the software is provided “as is,” without warranties of any kind. Microsoft and other copyright holders are not liable for any claims, damages, or other liabilities that may arise from the software’s use.
Microsoft’s release of the Phi-3.5 series represents a significant step forward in the development of multilingual and multimodal AI.
By offering these models under an open-source license, Microsoft empowers developers to integrate cutting-edge AI capabilities into their applications, fostering innovation across both commercial and research domains.
Source link